
This post documents the end-to-end process of deploying an autoscaling LLM inference endpoint on Google Kubernetes Engine using Cloud TPU v5e and vLLM. It covers everything from quota discovery to a live, serving deployment – including the parts that didn't go as planned.
This is an abridged version. The full article, all Kubernetes manifests, and helper scripts are available in the GitHub repository. The detailed writeup is published at xprilion.com/gemma3-vllm-tpu-gke-autoscaling.
The Goal
Deploy Gemma 4 on TPU v5e with HPA-based autoscaling driven by vLLM's built-in Prometheus metrics. The autoscaling stack uses Google Cloud Managed Prometheus, the Custom Metrics Stackdriver Adapter, and a HorizontalPodAutoscaler targeting num_requests_waiting.
What Actually Happened
TPU provisioning on GCP has three independent gates: regional TPU quota, a global accelerator cap called GPUS_ALL_REGIONS, and physical capacity. I had regional quota (16 chips) but GPUS_ALL_REGIONS was set to 0 – and despite the name, it blocks TPUs too, counted per chip. After testing six zones across three regions and hitting capacity exhaustion everywhere, the quota gate finally revealed itself once capacity opened up.
I requested 16 chips. Google's quota team offered 1. Anything beyond that requires Sales engagement. With a single chip (16GB HBM), I deployed Gemma 3 4B instead of the originally planned Gemma 4 26B.
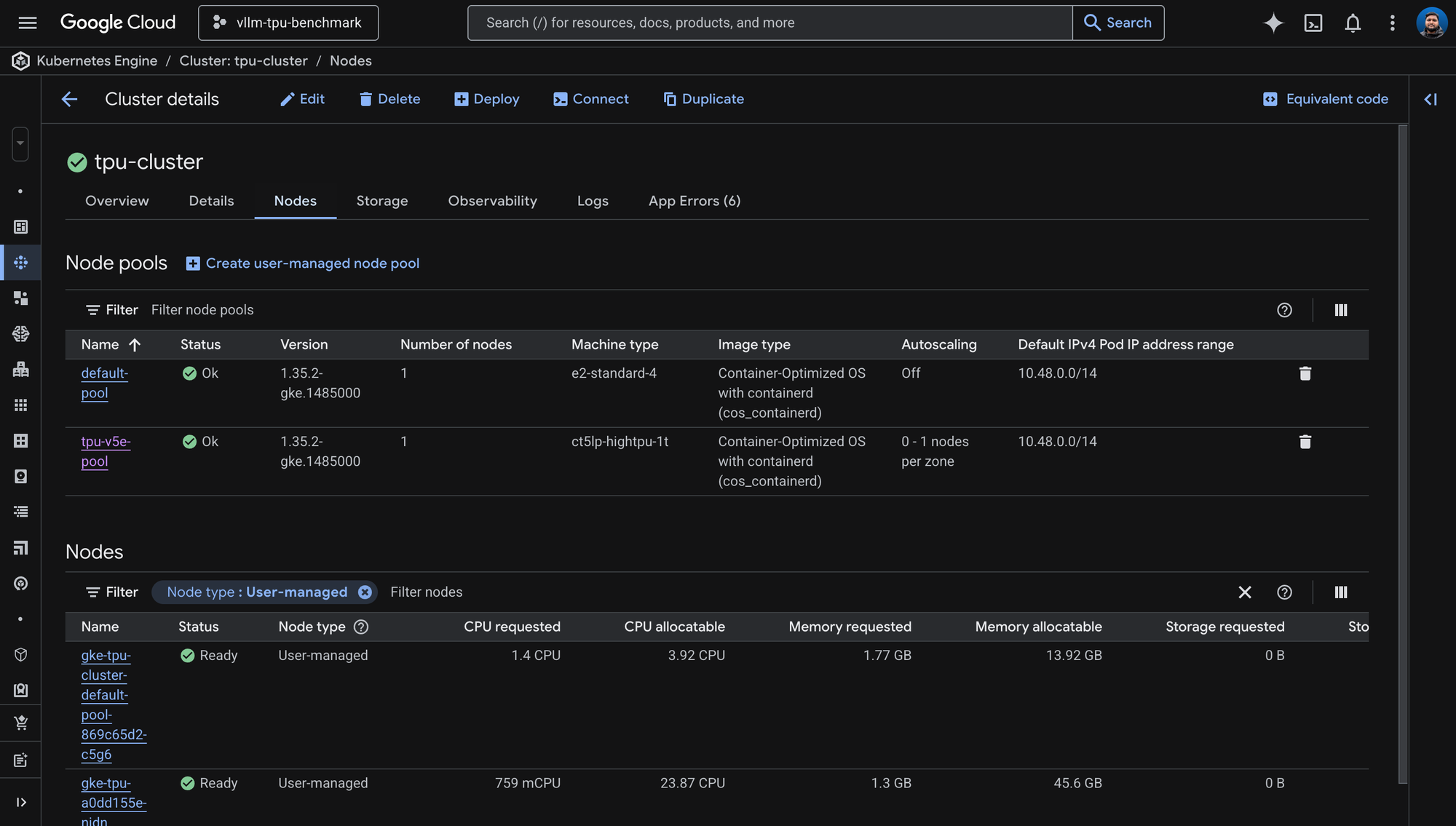 GKE Console showing the TPU cluster with both node pools healthy
GKE Console showing the TPU cluster with both node pools healthy
Gemma 4 Compatibility
I tested every Gemma 4 variant available on vLLM's TPU backend (both latest and nightly images). All four attempts failed. The stable image didn't recognize the gemma4 architecture. The nightly image got further but hit AssertionError: Expect no shared layers – Gemma 4 uses weight-tied layers that the tpu-inference backend doesn't support yet. This affects all Gemma 4 variants (E2B, E4B, 26B-A4B, 31B).
The Working Deployment
The final stack runs Gemma 3 4B on a single TPU v5e chip via vllm/vllm-tpu:nightly, with the full autoscaling infrastructure proven and operational. The HPA reads num_requests_waiting from Managed Prometheus and can scale the deployment from 1 to N replicas, which in turn triggers the GKE node pool autoscaler to provision additional TPU nodes.
 HPA output showing the metric pipeline working: 0/5 targets, 1 replica
The architecture scales to 8 chips and larger models by changing five configuration values: machine type, topology label, TPU count, tensor parallel size, and model name. Everything else - GCS FUSE caching, Workload Identity, PodMonitoring, HPA, load testing scripts – stays identical.
HPA output showing the metric pipeline working: 0/5 targets, 1 replica
The architecture scales to 8 chips and larger models by changing five configuration values: machine type, topology label, TPU count, tensor parallel size, and model name. Everything else - GCS FUSE caching, Workload Identity, PodMonitoring, HPA, load testing scripts – stays identical.
Conclusion
GPUS_ALL_REGIONSis the hidden gate. Check it before anything else.- TPU capacity errors auto-retry; quota errors are permanent. Know which you're hitting.
- GKE requires both
gke-tpu-acceleratorandgke-tpu-topologynode selectors. Missing either triggers a Warden rejection. - Build the full stack on minimal hardware first. Prove it works, then scale up.
The full article, all Kubernetes manifests, and helper scripts are available in the GitHub repository. The detailed writeup is published at xprilion.com/gemma3-vllm-tpu-gke-autoscaling.
This project was part of #TPUSprint by Google's AI Developer Programs team. Google Cloud credits were provided for this project.