Part 1 - Undestanding HADR systems
Let us begin by understanding a few basics of High Availability Disaster Recovery (HADR) systems. We'll cover a few key terms and then some common system topologies.
Key terms related to HADR systems
Key terms that you should know about HADR systems -
High Availability
High availability (HA) describes the ability of an application to withstand all planned and unplanned outages (a planned outage could be performing a system upgrade) and to provide continuous processing for business-critical applications.
Disaster Recovery
Disaster recovery (DR) involves a set of policies, tools, and procedures for returning a system, an application, or an entire data center to full operation after a catastrophic interruption. It includes procedures for copying and storing an installed system's essential data in a secure location, and for recovering that data to restore normalcy of operation.
Unplanned downtime
Downtime caused by factors which were not introduced on purpose is called unplanned downtime. This can be majorly due to:
Human Error
Software Problems
Hardware Failure
Environmental Issues

Planned downtime
The opposite of unplanned downtime.

Downtimes introduced on purpose, mostly are:
System upgrades
System repairs
Restricted access due to business reasons
Chaos Engineering
Chaos engineering is a method of testing distributed software that deliberately introduces failure and faulty scenarios to verify its resilience in the face of random disruptions. These disruptions can cause applications to respond in unpredictable ways and can break under pressure.
Resilience
The ability of a solution to absorb the impact of a problem in one or more parts of a system, while continuing to provide an acceptable service level to the business customers.
Key metrics for analyzing your system design
The key metrics used to analyze system designs are -
Production capacity in and out of region
Platform availability
Availability during planned outages
Failure Impact
Disaster recovery time
Incident response time
Next, let's look at some HADR system topologies, before we compare their metrics.
A 30,000ft view of high availability system design
HADR systems can be designed with several topologies ranging from simple ones - where you put all your eggs in a single basket - or complex ones - where you devise a fail-safe array of servers. Let us study a couple of them to understand how such topologies look like -
Consider the following 2-Active topology -
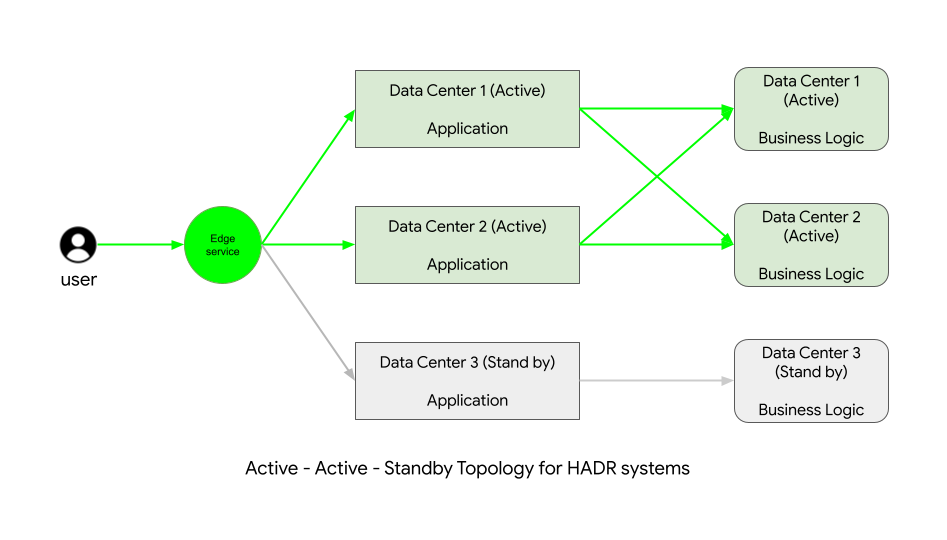
This topology shows that we provision 3 servers such that during normal operations, 2 servers load balance the traffic coming to the application while a third server stays on standby. This server gets activated in the event of failure of any or all of the active servers.
An alternative to a 2-Active system topology is a 3-Active topology -
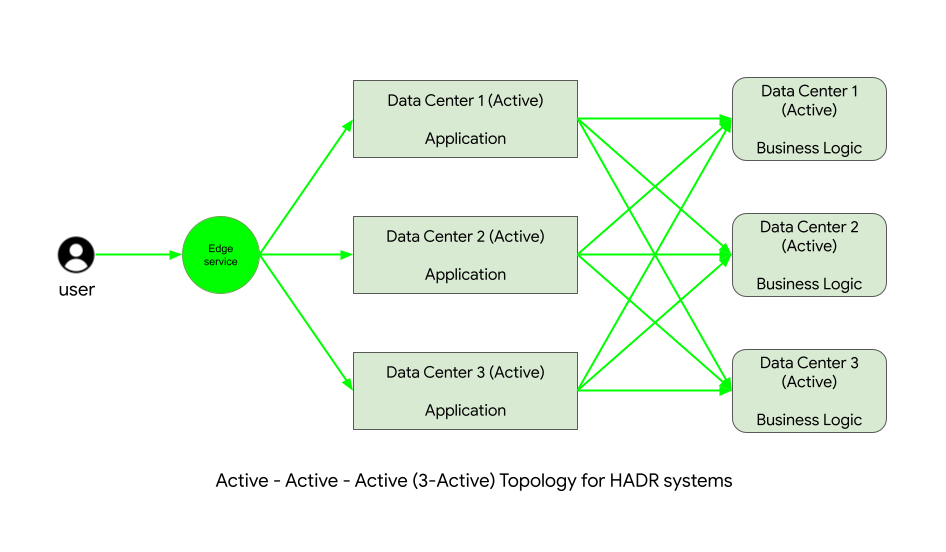
In this system topology, we provision all three servers as active servers and in event of failure of any server, the other servers load balance the traffic, while the failed servers are brought back up.
An obvious question here - which of these is better?
Consider the following chart of metrics comparison for the above two systems against a single Active system -
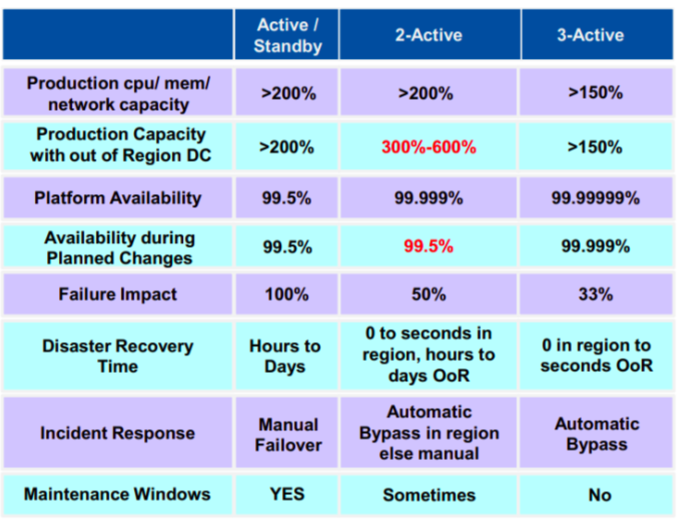
From the above, it can be said that while 3-active systems gives highest availability and lowest failure impacts, if your application is likely to expect surges, a 2-active system might give you better resilience.
We shall wrap our discussion about HADR system topologies here. Next, we'll talk about challenges posed by ML in HADR systems and see a demo of these topologies in action!